Last year I composed a series of convoluted posts detailing each team's odds of winning their respective conference tournaments, then composed a full set of probabilities for each NCAA Tournament team to make the Final Four. Despite a little rust on the prob/stat end due to my theatre exploits, I jogged my memory and quickly whipped out a full set of probabilities, adjusting for the new wonky 68 team format.
The new at-large play-in format doesn't adversely affect those teams' already dim chances of making the Sweet 16 or Final Four. We're talking about 11 and 12 seeds here, after all. These teams are already facing long odds of getting to the Final Four. At worst, playing in cuts those chances by 70%, and if so that team's probably not good enough to project getting far anyway. More than likely, a worthy Cinderella candidate only sees their chances drop by 1/3... for example a 12% shot to make the Final Four becomes a 9% shot... not a huge difference.
In the distant past I've gone over the formula for determining each team's odds of winning individual games based on Sagarin ratings, and determining their odds of reaching certain points in the tournament based on Markov formulas. I won't bore you now with the details but rest assured this isn't just a bunch of numbers and ideas I pulled out of my ass.
So now, here are the four regions and odds for each team in the region:
EAST
The only region with two play in games has a lot of wonky stuff going on aside from the bonus action, but this is pretty much Ohio State's region for the taking.
Dark horse: Washington (7). I'd say Kentucky at #4 but they'll run into consensus #1 team Ohio State in the Sweet 16, easily the team to beat this year, and Orange would be a 2 to 1 dog in that matchup: I don't foresee an upset. UW, however, is a deserving but dangerous 7 seed that, for all their ups and downs (and legal trouble) this year, can play with just about anyone in the country. If they faced overseeded #2 UNC in round two I'd actually have the Huskies as the slight favorite, and think #3 Syracuse would give them a tougher but winnable challenge in the Sweet 16. Don't be too shocked if Ohio State ends up facing UW in the regional final. I won't say the Huskies would win... but they could certainly give the Buckeyes a scare at the least, and scoring the upset isn't impossible.
Overseeded: North Carolina (2) and Xavier (6). Reputation's pretty much carrying UNC in a down year: They're more like a 4 this year. Three teams below them (Syracuse, Kentucky, Washington) would be favorites to beat them on a neutral floor. Roy Williams' team would be fortunate to make the 2nd weekend, dad gummit. Xavier is more of a double digit seed, such a bad misseeding by the committee that they may have table-set a 1st round upset (more in a bit).
Underseeded: Clemson (12) and Marquette (11). Clemson did not have the best year but they should not be playing in when they're better than at least 4-5 other at-large teams, if not more. Marquette also got unduly punished, and probably deserved a single digit seed. 1st round opponent Xavier is similarly mismatched, and don't be surprised if Marquette sends Xavier packing.
No chance in hell: Neither 16 seed poses any sort of credible threat. Texas-San Antonio's odds at the Final Four are suitably long at 430,000 to 1, but the odds for Alabama State, easily the weakest team in this 68 team field, are so laughably long they make Powerball look like a better bet: 69,000,000 to 1. That is not an exaggeration. Their odds of getting to the round of 32 alone are 612 to 1 and their odds of making the 2nd weekend are roughly 23,800 to 1.
You have a better chance of... dying in a tsunami (condolences, Japan). In fact, you're more than ten times more likely to die randomly in a tsunami (615,488 to 1). Those odds obviously go up if you live on coastline in a fault zone, but still.
At least their odds are better than the odds of winning Powerball: 195,000,000 to 1.
Odds:
1. Ohio State. Sweet 16: 79.3%. Final Four: 1.4 to 1 (41.5%)
2. North Carolina. Sweet 16: 46.2%. Final Four: 9.5 to 1
3. Syracuse. Sweet 16: 59.4%. Final Four: 7.2 to 1
4. Kentucky. Sweet 16: 59.4%. Final Four: 6.0 to 1
5. West Virginia. Sweet 16: 26.4%. Final Four: 27.3 to 1
6. Xavier. Sweet 16: 14.6%. Final Four: 96.9 to 1
7. Washington. Sweet 16: 45.1%. Final Four: 8.3 to 1
8. George Mason. Sweet 16: 7.8%. Final Four: 96.7 to 1
9. Villanova. Sweet 16: 12.8%. Final Four: 42.4 to 1
10. Georgia. Sweet 16: 6.9%. Final Four: 271 to 1
11. Marquette. Sweet 16: 23.7%. Final Four: 38.9 to 1
12. UAB. Sweet 16: 2.8%. Final Four: 861 to 1
12. Clemson. Sweet 16: 8.8%. Final Four: 131 to 1
13. Princeton. Sweet 16: 2.6%. Final Four: 2488 to 1
14. Indiana State. Sweet 16: 2.3%. Final Four: 4125 to 1
15. Long Island. Sweet 16: 1.8%. Final Four: 4331 to 1
16. Texas San Antonio. Sweet 16: 0.1%. Final Four: 430,000 to 1
16. Alabama State. Sweet 16: LOL. Final Four: 69,000,000 to 1
WEST
A more conventional 16 team region also has a conventional favorite, as Duke like OSU is facing considerable odds (41%) of making the Final Four. Few teams here can pose a serious challenge for them.
Dark Horse: San Diego State (2) and Texas (4). Silly to cite two high seeds as dark horses, but these are pretty much the best teams in the field not named Duke and the only real challengers to the Blue Devils. Texas is only a 60-40 dog to Duke and if they pulled the upset they'd be the favorite against every possible opponent. SDSU would be a 2 to 1 dog vs Duke in the Elite Eight and a 56-44 dog to Texas if the Longhorns pulled the upset but would be the favorite against anyone else. The odds for either aren't terrific, around 9 to 2 or 5 to 1, but they have the most realistic chance of everyone else to pull it off.
Overseeded: Tennessee (9) and Memphis (12). The Volunteers probably deserved a double digit seed, while Memphis' reputational license has long since expired. They won their conference tourney to get in, but they pack little more punch than your run of the mill mid-major these days, and probably belongs in the 13-14 range. Don't count on a 5-12 upset when Memphis meets legit 5 seed Arizona, while Tennessee has a reasonable shot at a round one win but stands little chance against Duke in the 32-round.
Underseeded: Texas (4) and Missouri (11). Texas has the strength of a 2, and if they meet Duke in the Sweet 16 as expected they will likely pose the toughest challenge of the bracket to the Blue Devils. Missouri probably warrants a middle seed more than a bubble seed, and likely no one will notice because Cincinnati at 6 is pretty good and is a slight 54-46 favorite to dispatch the Tigers, who deserved better.
No chance in hell: 16 seed Hampton is already a 50 to 1 dog to beat Duke in round one. Their odds of going all the way to the Final Four? A paltry 100,000 to 1.
You have a better chance of... sinking a hole in one from 150 yards (80,000 to 1). Maybe Hampton should bag the tourney and join the golf team for a relaxing weekend that doesn't involve getting crushed by 30 points against a Duke team running at half speed.
Odds:
1. Duke. Sweet 16: 82.8%. Final Four: 1.4 to 1 (41.2%)
2. San Diego State. Sweet 16: 65.3%. Final Four: 4.8 to 1
3. Connecticut. Sweet 16: 45.4%. Final Four: 12.4 to 1
4. Texas. Sweet 16: 59.9%. Final Four: 4.6 to 1
5. Arizona. Sweet 16: 30.2%. Final Four: 21.9 to 1
6. Cincinnati. Sweet 16: 28.2%. Final Four: 24 to 1
7. Temple. Sweet 16: 18.6%. Final Four: 54.1 to 1
8. Michigan. Sweet 16: 9.7%. Final Four: 90.9 to 1
9. Tennessee. Sweet 16: 7.2%. Final Four: 153 to 1
10. Penn State. Sweet 16: 13.8%. Final Four: 93.7 to 1
11. Missouri. Sweet 16: 22.9%. Final Four: 35.5 to 1
12. Memphis. Sweet 16: 3.5%. Final Four: 1133 to 1
13. Oakland. Sweet 16: 6.4%. Final Four: 315 to 1
14. Bucknell. Sweet 16: 3.4%. Final Four: 1568 to 1
15. Northern Colorado. Sweet 16: 2.4%. Final Four: 2974 to 1
16. Hampton. Sweet 16: 0.3%. Final Four: 100,000 to 1
SOUTHWEST
The odds of someone other than the top seed get a little better here, but not by much,a s top seed Kansas has a 34.6% chance of making the Final Four. However, the challenge is more broad and general, with no specific dark horses posing a threat aside from....
Dark horse: Purdue (3). Purdue might be a touch underseeded but it makes little difference at 3. They are a do-able 62-38 dog against Kansas if they meet in the regional final, and are solid (though typically not dominant) favorites against anyone else in the field, even 2 seed Notre Dame. Their chances of making the Elite Eight are a solid 39.5%, and there's a 47% chance Kansas falls before that point, which would make the Boilermakers a favorite to make the Final Four.
Overseeded: Both 11 seeds in the region's play-in game: USC and VCU. Actually, "shouldn't be in the tournament at all" is a better label. Given the snubs (Colorado, St Mary's, New Mexico), and how low both of these teams rate overall, the fact that either of these teams are playing championship basketball at all is insulting. Neither objectively is close to being a bubble team, and yet here they are. USC is a 69-31 favorite in the game, and a 74-26 dog against a far superior #6 Georgetown team. 12 seed Richmond could wipe the floor with both these play-in jokes.
Underseeded: UNLV (8) and Illinois (9). Both these 1st round opponents should be a couple seeds higher. If not playing each other for the right to get force-fed to Kansas, both would have a very good shot at the 2nd weekend.
No chance in hell: Newcomer St Peter's (14) faces some fairly long odds at 11,000 to 1 thanks to drawing tough Purdue in round one, making them a 13 to 1 dog for the upset. They probably should have been a 15 but debating the low seeds is a quibble. Our 16 in this bracket, Boston U, is facing 53,600 to 1 odds, and 33 to 1 odds of getting past top seeded Kansas. Even given that, the Terriers have the best chances of any 16 seed in the field.
Odds:
1. Kansas. Sweet 16: 72.3%. Final Four: 1.9 to 1 (34.6%)
2. Notre Dame. Sweet 16: 61.8%. Final Four: 6.8 to 1
3. Purdue. Sweet 16: 62.1%. Final Four: 4.1 to 1
4. Louisville. Sweet 16: 56.9%. Final Four: 8.2 to 1
5. Vanderbilt. Sweet 16: 26.0%. Final Four: 33.8 to 1
6. Georgetown. Sweet 16: 23.0%. Final Four: 25.4 to 1
7. Texas A&M. Sweet 16: 18.1%. Final Four: 65.3 to 1
8. UNLV. Sweet 16: 12.9%. Final Four: 37.1 to 1
9. Illinois. Sweet 16: 14.6%. Final Four: 30.1 to 1
10. Florida State. Sweet 16: 18.2%. Final Four: 65.0 to 1
11. USC. Sweet 16: 7.5%. Final Four: 141 to 1
11. VCU. Sweet 16: 1.1%. Final Four: 2911 to 1
12. Richmond. Sweet 16: 14.3%. Final Four: 105 to 1
13. Morehead State. Sweet 16: 2.8%. Final Four: 2818 to 1
14. St Peter's. Sweet 16: 0.9%. Final Four: 11,000 to 1
15. Akron. Sweet 16: 1.9%. Final Four: 5832 to 1
16. Boston U. Sweet 16: 0.3%. Final Four: 53,600 to 1
SOUTHEAST
The weakest (1) seed in Pittsburgh has a somewhat serious challenger and perhaps a couple of dim challengers to their Final Four throne. This region is rather seed, chock full of mid majors, only some of which pose a serious threat one on one, and many are underseeded, forcing them to climb uphill for the right to try and knock off the Panthers. But that said, Pittsburgh's weak-favorite status means there's a 68% chance someone else will represent the Southeast region in the Final Four, with over half the teams having roulette-like odds at doing so.
Dark Horse: BYU (3). Even without dismissed Brandon Davies, the Mormon Cougars have a solid top ten ballclub, and are no worse than a slight underdog to anyone. A couple of breaks and they could sneak past Pitt into the Final Four. Only a lack of dominant strength makes them a somewhat distant shot at 20.7%. Wisconsin (4) is close in strength but is slated to run into Pittsburgh in the Sweet 16 if they get that far.
Overseeded: Florida (2) and UCLA (7). The weakest two seed in the field should be a 5 or even lower. A very weak sub-bracket (UCLA at 7 and a downish Michigan State at 10, and of course the Gators draw the easily beatable 15 seed UCSB in round one) gives them an even money chance to get to the 2nd weekend, but BYU would be a 2 to 1 favorite if they met in the Sweet 16, and even #6 St John's could give them a serious game.
I had UCLA on the bubble, but they got a 7 seed. Ridiculous. They're a 56-44 underdog to Michigan State in the 1st round.
Underseeded: Utah State (12) and Belmont (13). Look, I know mid majors play weak schedules and you have to bear that in mind when they, say, win 30 games comfortably and only lose to top 50 opponents. But weak scheds never stopped the NCAA in previous years from giving Tark's UNLV teams or old powerhouse Memphis teams high seeds. Hell, Princeton teams in the 90's got single digit seeds a few times, and they rarely played anybody during the regular season.
Oh, but they never go far in the tourney anyway, right? The reason you never see these Utah States and Belmonts go far in the tourney is because you keep giving them 12 and 13 seeds and they're forced to play a tough 4 or 5 seed in the first round instead of some middling power conference team that they could beat. Are the powers that be afraid of getting their conferences exposed as overrated in an NCAA Div-I with better parity? Are they afraid of Utah State pulling a Gonzaga and showing they could go deep and that maybe these perennially successful small schools can play with the big boys and deserve respect?
Anyway, watch out for the 5-12 upset special here, as (5) Kansas State is a slight 47-53 underdog to Utah State. Belmont is not so lucky at 13: (4) Wisconsin is the real deal and a 64-36 favorite.
Speaking of Gonzaga, they're not what they used to be, but they're a slight 52-48 favorite at (11) to topple (6) St John's. Expect many upsets in this region. But not from....
No chance in hell: Arkansas Little Rock is a gift... for Pittsburgh, that is, if they can overcome 2 to 1 favorite UNC Asheville in the play in game. UALR is a 173,000 to 1 shot to thread the needle and make the Final Four.
You have a better chance of: Being killed on the job if you're a teacher or nurse (143,000 to 1). Education majors at UALR can both take comfort and weep at these facts.
Odds:
1. Pittsburgh. Sweet 16: 75.6%. Final Four: 2.1 to 1
2. Florida. Sweet 16: 52.4%. Final Four: 9 to 1
3. BYU. Sweet 16: 58.7%. Final Four: 3.8 to 1
4. Wisconsin. Sweet 16: 41.3%. Final Four: 6.9 to 1
5. Kansas State. Sweet 16: 18.2%. Final Four: 33.2 to 1
6. St John's. Sweet 16: 18.1%. Final Four: 31.2 to 1
7. UCLA. Sweet 16: 18.3%. Final Four: 58.9 to 1
8. Butler. Sweet 16: 13.5%. Final Four: 61.7 to 1
9. Old Dominion. Sweet 16: 9.9%. Final Four: 108 to 1
10. Michigan State. Sweet 16: 25.8%. Final Four: 30.6 to 1
11. Gonzaga. Sweet 16: 20.1%. Final Four: 25.9 to 1
12. Utah State. Sweet 16: 22.2%. Final Four: 23.5 to 1
13. Belmont. Sweet 16: 18.2%. Final Four: 29.9 to 1
14. Wofford. Sweet 16: 3.1%. Final Four: 840 to 1
15. UC Santa Barbara. Sweet 16: 3.5%. Final Four: 1649 to 1
16. UNC Asheville. Sweet 16: 0.9%. Final Four: 7729 to 1
16. Ark Little Rock. Sweet 16: 0.1%. Final Four: 173,000 to 1

Showing posts with label sagarin ratings. Show all posts
Showing posts with label sagarin ratings. Show all posts
Tuesday, March 15, 2011
Sunday, November 29, 2009
Ballhype, Golden Picks and EV, Part 4: Devising and applying a method to determine probability with Sagarin Predictor Ratings
The Sagarin ratings have to also correlate to a team's probability to win, I thought. A team with a slightly higher rating than another team probably wasn't as strong a favorite as a team whose rating was 15-20 points ahead of their opponent.
I went to Google and searched for data on Sagarin and Probability. Many articles had a narrow focus, whether on their respective team or on yet another failed (and poorly researched) attempt to beat the sportsbooks with the data without any preliminary research. My previous observations showed that the final scores in any sport deviated so greatly from the point differential in Sagarin ratings that using them to determine a margin of victory was practically pointless as they were... though they still remained an accurate determinant of which team would win.
I landed on some data relating to Sagarin's ELO Chess number (which simply judges team resume strength by who they won and loss to with no regard to final scores)... that illustrated how you can use a chess player's rating in a 1500 point system to determine the probability of one player beating the other. The article by Brian Burke illustrates how a chess rating is determined on a match to match basis, and the workings of the algorithm that determines win probability for each player before a given match. The formulas may make your head explode unless you've seen Trig, Intermediate Algebra or Calculus level math before.
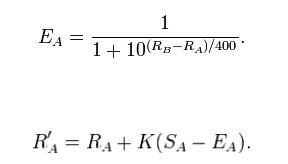
The rating formula, however, does a fine job of weighing the quality of a victory and using outcomes to determine a player or team's actual strength from their track record. And the probability formula provides an accurate correlative probability for each player's chances of victory.
Burke wrote that article in the context of evaluating the Sagarin rating system, and since Sagarin himself based the method off of the chess rating system, it would stand to reason that his ratings could in turn be used similarly to determine a team's probability of winning. Of course, using the formulas directly would not work since ELO Chess uses a 1500 point rating scale, and Sagarin's rating scale (where most ratings are around the 50-100 point mark) is distinctively different.
A similar rendition of the probability equation is shown here on the Pro Football Reference blog, where instead of the static factors of 10 and 400, factors of e (2.718281828...) and a different equation utilizing the control factor of -0.15:
Win Probability = 1 / (1 + e^(-.15*(rating difference)))
This formula always returns a value between 0 and 1, which can be translated into a percentage chance of victory.
Armed with OpenOffice Spreadsheet Power, I opened up a spreadsheet and tinkered my way to a template on which I could enter two competing teams' Sagarin ratings (with the requisite rating adjustment for the home team) and have a function spit out the home team's chance for victory:
=1/(1+(e^(-0.15*((home team's rating + home team bonus)-road team's rating))))
Convoluted? Basically, the difference between the home team (with their bonus) and the road team is multiplied by -0.15. Then the factor e (2.718281828...) is taken to the power of whatever number the first equation adds up to. That answer is added to 1, and then 1 divided by the answer to the last equation is the home team's chance of winning.
Because I enjoy crunching all this by hand as much as you do, I opened up an OpenOffice spreadsheet and plugged the formula into a simplistic interface that would allow me to just plug in Sagarin Predictor ratings (which Sagarin vouches is the most effective of his three given ratings in predicting outcomes, as they factor in final scores) and get a quick probability for the home team.
With no other specific data out there to verify or deny using the formula this way with Sagarin ratings, I plugged in a few Sagarin ratings for upcoming matchups, and the results I got were fairly consistent. To wit, top 25 teams often sported 95-98% chances of beating small college scrubs. If there's any data out there that provides a more accurate method for matching Sagarin ratings to probability, I have yet to find it.
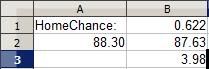
Cell B3 contains the home team bonus (which varies by sport). Cell A2 holds the visiting team's rating and B2 the home team's. I plugged the formula in at cell B1, which spits out a probability for the home team.
Above are ratings for two teams whose identities I have since forgotten (though from the 3.98 home bonus I recognize the teams are from NCAA College Basketball). The road team's 88.30 rating and home team's 87.63 rating with 3.98 bonus indicates that the home team has a 62.2% chance of winning their game, which makes sense: In a basketball matchup between two roughly equal teams (which these two are), the home team tends to win 60-65% of the time.
(One aside: A common misinformed complaint about Sagarin's Predictor rating is that a huge blowout can artifically inflate a team's rating. However, the rating process actually follows a law of diminishing returns: For example, in determining the Predictor rating, a 35-0 victory adds more to a team's rating than a 14-10 victory... but a 70-0 victory doesn't add all that much more than a 35-0 victory. Both blowouts add roughly the same amount in rating strength.
Likewise, in determining win probability... the greater the difference in ratings, the greater the probability the favorite will win... but as the difference increases in size, the amount of winning probability added to the favorite's chances reduces in scope. The PFR article includes a helpful graph to illustrate:
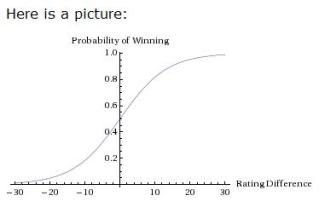
Much like a bell curve, the chances of winning change dramatically as the difference between teams goes up from 0... but as the difference reaches a high margin, the chances of the favorite winning flatten out around the 95-98% mark, which makes sense since, after all, you can't go past 100% and if any team really had a 100% chance of winning, there'd never be any Appalachian State over Michigan level upsets and there'd be no point in playing the game.
Now... going back to Ballhype's Golden Picks Contest, the value of a pick is directly proportional to how many other people have picked each particular team to win. The more people that pick one team, the fewer points each person gets when the favorite wins, which diminishes the value of picking the favorite as each additional person selects that favorite to win.
Lisewise, the more people that pick a favorite, the more value there is in picking the underdog, as you'll then get more points if the underdog wins. At the same time, the more people that pick the underdog, the less value you get in picking the underdog, as each additional person dilutes the split each person gets for a successful underdog pick... and in turn, the more value that subsequently comes in picking the favorite, since those who pick the winning team get an additional point for each person that selects an unsuccessful underdog.
Amidst all this, there is one constant: Every incorrect pick is always worth -1 point, regardless of whether your incorrect pick was a favorite or underdog. That's where the Hensley Strategy succeeds: There is a stop-loss limit of -1 point for every wrong pick, but no ceiling on the point value of successful underdog picks. With every additional person picking the favorite, you get an additional point if you're picking the underdog and the upset happens. With a shallow ceiling for failure and a ceilingless potential with success, picking underdogs typically carries a positive EV.
The thing is, picking an underdog does not always produce a positive EV. There is a point where a favorite is such a huge favorite that a large number of people would need to pick the favorite for an underdog pick to have a positive EV.
The point of all this is that I expanded my meager spreadsheet with a pair of separate EV functions that factored in the calculated probabilities of each team, the number of picks for each team on the contest, and the expected value of each respective pick:
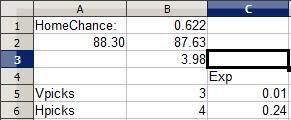
In Cell B5 I enter the number of current picks in the contest for the visitor and picks for the home team in Cell B6. Column C6 determines the EV of picking the home team with the following formula:
=(Home team probability *(Number of total points for correct pick divided by number of players making this pick)+((Road team's win probability)*(-1 point for losing)))
Basically, I take the probability of a win times the possible points I can earn for winning, then add together the probability of losing (the other team winning) times -1 point. The formula is flipped over for the road team, and the expected value of each respective pick is listed under "Exp" for both picks. Currently, the 3 people who picked the road team have an expected value of 0.01 point... barely above zero and just a shred more valuable than not having made the pick at all. The 4 people who selected the home team have an EV of 0.24 point, meaning the pick has a positive expected value, a smart pick....
... for now. See, other people may make a pick between now and game time, and every pick can affect the expected value of a pick, even though the probabilities aren't going to change, since every pick affects the potential point distribution for the winner.
Let's see what happens when I decide to pick the road team.
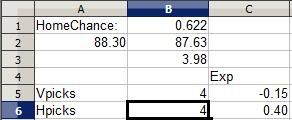
The EV for picking the road team immediately drops to -0.15 points, making it a bad pick in the same sense that playing craps is a negative EV decision. In craps, the odds make it so that the House will take your money in the long run. If I were put in this same situation an infinite number of times and made this exact same pick, I would lose an average of 0.15 points for each time I made the pick. It's a losing pick: The points I win every time the road team succeeds are not worth as much as the point I lose every time the home team wins. Sure, the road team may win and it's all moot, but the combination of the odds and the potential value show that this is a bad pick.
Now, let's see what happens when I flip flop and pick the home team instead.
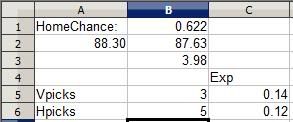
The value of picking the home team also decreases (a pick's EV is always going to decrease when you make it because you're diluting the payout by adding a person to divide it with). But in declining, the EV of the selection remains positive. If placed in this situation an infinite number of times, I would gain an average of 0.12 points for each time I picked: The value of a win here is going to be worth more than all the times I lose a point when the pick fails.
Thus, it's clear in this instance that I ought to pick the home team to win. Sure, in this case I'm picking the favorite, but it's not always worthwhile to pick the favorite. Here's an example where picking an underdog may be a good decision:
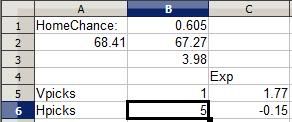
This college basketball matchup I remember: Pepperdine traveled to Wyoming for a non-conference game. Both teams are fairly so-so but roughly equal, making the home team Wyoming a 60.5% favorite. However, as you can see five other players had already selected Wyoming while only one had selected Pepperdine, making the Wyoming selection a negative EV pick for everyone involved while the Pepperdine pick was an overwhelmingly positive EV pick. So I went ahead and picked the underdog Pepperdine:
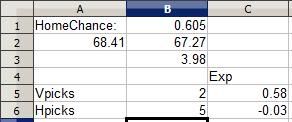
As you can see, the reduced EV was still overwhelmingly positive, making the Pepperdine pick a more profitable pick. Even if Pepperdine goes on to lose as predicted, the value the Wyoming selectors got from their pick was negative. Results based analysis would say they're right, but probability analysis shows that making that pick 1000 times would be a loser in the long run. A somewhat-unlikely Pepperdine upset would yield more value for Pepperdine selectors than a likely Wyoming win would net for Wyoming selectors.
Now, this doesn't necessarily mean picking a favorite in Ballhype is a bad value, or that picking a big underdog is necessarily a good value. Sometimes a team is such a large favorite that even if their win would net a selector a very small score and that an upset would net an underdog pick a huge score... the odds are so great that the favorite will win that picking the underdog is pointless.
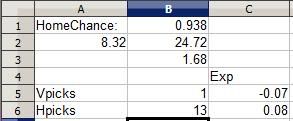
This is from this week's NFL matchup between the Cleveland Browns and Cincinnati Bengals in Cincinnati. The Browns' rating is clearly horrid in comparison to Cincinnati's and the Bengals are a huge 93.8% favorite. Even with a whopping 13 other selectors diluting the Bengals pick, the Bengals remain a positive (albeit small) EV pick while the Browns remain a negative pick, simply because the odds of the talented Bengals defeating the woeful Browns is so great. I add my pick to the fray:
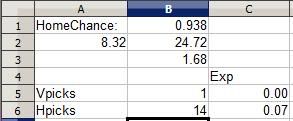
Notice how the EV remains positive for the Bengals pick. A Bengals win nets 0.14 point, but the chance of earning that point is so great and the chances of a crushing -1 point upset are so small that the Bengals pick is still a smart one, while picking the Browns is foolish despite the 14 point potential, akin to putting your money on a couple of roulette numbers (a more than 35 to 1 shot for each number) and hoping one happens to hit. (The Bengals did go on to win this early game 16-7)
It is with this methodology that I went to work on picking Friday's games... to be covered in Part 5.
I went to Google and searched for data on Sagarin and Probability. Many articles had a narrow focus, whether on their respective team or on yet another failed (and poorly researched) attempt to beat the sportsbooks with the data without any preliminary research. My previous observations showed that the final scores in any sport deviated so greatly from the point differential in Sagarin ratings that using them to determine a margin of victory was practically pointless as they were... though they still remained an accurate determinant of which team would win.
I landed on some data relating to Sagarin's ELO Chess number (which simply judges team resume strength by who they won and loss to with no regard to final scores)... that illustrated how you can use a chess player's rating in a 1500 point system to determine the probability of one player beating the other. The article by Brian Burke illustrates how a chess rating is determined on a match to match basis, and the workings of the algorithm that determines win probability for each player before a given match. The formulas may make your head explode unless you've seen Trig, Intermediate Algebra or Calculus level math before.
The rating formula, however, does a fine job of weighing the quality of a victory and using outcomes to determine a player or team's actual strength from their track record. And the probability formula provides an accurate correlative probability for each player's chances of victory.
Burke wrote that article in the context of evaluating the Sagarin rating system, and since Sagarin himself based the method off of the chess rating system, it would stand to reason that his ratings could in turn be used similarly to determine a team's probability of winning. Of course, using the formulas directly would not work since ELO Chess uses a 1500 point rating scale, and Sagarin's rating scale (where most ratings are around the 50-100 point mark) is distinctively different.
A similar rendition of the probability equation is shown here on the Pro Football Reference blog, where instead of the static factors of 10 and 400, factors of e (2.718281828...) and a different equation utilizing the control factor of -0.15:
Win Probability = 1 / (1 + e^(-.15*(rating difference)))
This formula always returns a value between 0 and 1, which can be translated into a percentage chance of victory.
Armed with OpenOffice Spreadsheet Power, I opened up a spreadsheet and tinkered my way to a template on which I could enter two competing teams' Sagarin ratings (with the requisite rating adjustment for the home team) and have a function spit out the home team's chance for victory:
=1/(1+(e^(-0.15*((home team's rating + home team bonus)-road team's rating))))
Convoluted? Basically, the difference between the home team (with their bonus) and the road team is multiplied by -0.15. Then the factor e (2.718281828...) is taken to the power of whatever number the first equation adds up to. That answer is added to 1, and then 1 divided by the answer to the last equation is the home team's chance of winning.
Because I enjoy crunching all this by hand as much as you do, I opened up an OpenOffice spreadsheet and plugged the formula into a simplistic interface that would allow me to just plug in Sagarin Predictor ratings (which Sagarin vouches is the most effective of his three given ratings in predicting outcomes, as they factor in final scores) and get a quick probability for the home team.
With no other specific data out there to verify or deny using the formula this way with Sagarin ratings, I plugged in a few Sagarin ratings for upcoming matchups, and the results I got were fairly consistent. To wit, top 25 teams often sported 95-98% chances of beating small college scrubs. If there's any data out there that provides a more accurate method for matching Sagarin ratings to probability, I have yet to find it.
Cell B3 contains the home team bonus (which varies by sport). Cell A2 holds the visiting team's rating and B2 the home team's. I plugged the formula in at cell B1, which spits out a probability for the home team.
Above are ratings for two teams whose identities I have since forgotten (though from the 3.98 home bonus I recognize the teams are from NCAA College Basketball). The road team's 88.30 rating and home team's 87.63 rating with 3.98 bonus indicates that the home team has a 62.2% chance of winning their game, which makes sense: In a basketball matchup between two roughly equal teams (which these two are), the home team tends to win 60-65% of the time.
(One aside: A common misinformed complaint about Sagarin's Predictor rating is that a huge blowout can artifically inflate a team's rating. However, the rating process actually follows a law of diminishing returns: For example, in determining the Predictor rating, a 35-0 victory adds more to a team's rating than a 14-10 victory... but a 70-0 victory doesn't add all that much more than a 35-0 victory. Both blowouts add roughly the same amount in rating strength.
Likewise, in determining win probability... the greater the difference in ratings, the greater the probability the favorite will win... but as the difference increases in size, the amount of winning probability added to the favorite's chances reduces in scope. The PFR article includes a helpful graph to illustrate:
Much like a bell curve, the chances of winning change dramatically as the difference between teams goes up from 0... but as the difference reaches a high margin, the chances of the favorite winning flatten out around the 95-98% mark, which makes sense since, after all, you can't go past 100% and if any team really had a 100% chance of winning, there'd never be any Appalachian State over Michigan level upsets and there'd be no point in playing the game.
Now... going back to Ballhype's Golden Picks Contest, the value of a pick is directly proportional to how many other people have picked each particular team to win. The more people that pick one team, the fewer points each person gets when the favorite wins, which diminishes the value of picking the favorite as each additional person selects that favorite to win.
Lisewise, the more people that pick a favorite, the more value there is in picking the underdog, as you'll then get more points if the underdog wins. At the same time, the more people that pick the underdog, the less value you get in picking the underdog, as each additional person dilutes the split each person gets for a successful underdog pick... and in turn, the more value that subsequently comes in picking the favorite, since those who pick the winning team get an additional point for each person that selects an unsuccessful underdog.
Amidst all this, there is one constant: Every incorrect pick is always worth -1 point, regardless of whether your incorrect pick was a favorite or underdog. That's where the Hensley Strategy succeeds: There is a stop-loss limit of -1 point for every wrong pick, but no ceiling on the point value of successful underdog picks. With every additional person picking the favorite, you get an additional point if you're picking the underdog and the upset happens. With a shallow ceiling for failure and a ceilingless potential with success, picking underdogs typically carries a positive EV.
The thing is, picking an underdog does not always produce a positive EV. There is a point where a favorite is such a huge favorite that a large number of people would need to pick the favorite for an underdog pick to have a positive EV.
The point of all this is that I expanded my meager spreadsheet with a pair of separate EV functions that factored in the calculated probabilities of each team, the number of picks for each team on the contest, and the expected value of each respective pick:
In Cell B5 I enter the number of current picks in the contest for the visitor and picks for the home team in Cell B6. Column C6 determines the EV of picking the home team with the following formula:
=(Home team probability *(Number of total points for correct pick divided by number of players making this pick)+((Road team's win probability)*(-1 point for losing)))
Basically, I take the probability of a win times the possible points I can earn for winning, then add together the probability of losing (the other team winning) times -1 point. The formula is flipped over for the road team, and the expected value of each respective pick is listed under "Exp" for both picks. Currently, the 3 people who picked the road team have an expected value of 0.01 point... barely above zero and just a shred more valuable than not having made the pick at all. The 4 people who selected the home team have an EV of 0.24 point, meaning the pick has a positive expected value, a smart pick....
... for now. See, other people may make a pick between now and game time, and every pick can affect the expected value of a pick, even though the probabilities aren't going to change, since every pick affects the potential point distribution for the winner.
Let's see what happens when I decide to pick the road team.
The EV for picking the road team immediately drops to -0.15 points, making it a bad pick in the same sense that playing craps is a negative EV decision. In craps, the odds make it so that the House will take your money in the long run. If I were put in this same situation an infinite number of times and made this exact same pick, I would lose an average of 0.15 points for each time I made the pick. It's a losing pick: The points I win every time the road team succeeds are not worth as much as the point I lose every time the home team wins. Sure, the road team may win and it's all moot, but the combination of the odds and the potential value show that this is a bad pick.
Now, let's see what happens when I flip flop and pick the home team instead.
The value of picking the home team also decreases (a pick's EV is always going to decrease when you make it because you're diluting the payout by adding a person to divide it with). But in declining, the EV of the selection remains positive. If placed in this situation an infinite number of times, I would gain an average of 0.12 points for each time I picked: The value of a win here is going to be worth more than all the times I lose a point when the pick fails.
Thus, it's clear in this instance that I ought to pick the home team to win. Sure, in this case I'm picking the favorite, but it's not always worthwhile to pick the favorite. Here's an example where picking an underdog may be a good decision:
This college basketball matchup I remember: Pepperdine traveled to Wyoming for a non-conference game. Both teams are fairly so-so but roughly equal, making the home team Wyoming a 60.5% favorite. However, as you can see five other players had already selected Wyoming while only one had selected Pepperdine, making the Wyoming selection a negative EV pick for everyone involved while the Pepperdine pick was an overwhelmingly positive EV pick. So I went ahead and picked the underdog Pepperdine:
As you can see, the reduced EV was still overwhelmingly positive, making the Pepperdine pick a more profitable pick. Even if Pepperdine goes on to lose as predicted, the value the Wyoming selectors got from their pick was negative. Results based analysis would say they're right, but probability analysis shows that making that pick 1000 times would be a loser in the long run. A somewhat-unlikely Pepperdine upset would yield more value for Pepperdine selectors than a likely Wyoming win would net for Wyoming selectors.
Now, this doesn't necessarily mean picking a favorite in Ballhype is a bad value, or that picking a big underdog is necessarily a good value. Sometimes a team is such a large favorite that even if their win would net a selector a very small score and that an upset would net an underdog pick a huge score... the odds are so great that the favorite will win that picking the underdog is pointless.
This is from this week's NFL matchup between the Cleveland Browns and Cincinnati Bengals in Cincinnati. The Browns' rating is clearly horrid in comparison to Cincinnati's and the Bengals are a huge 93.8% favorite. Even with a whopping 13 other selectors diluting the Bengals pick, the Bengals remain a positive (albeit small) EV pick while the Browns remain a negative pick, simply because the odds of the talented Bengals defeating the woeful Browns is so great. I add my pick to the fray:
Notice how the EV remains positive for the Bengals pick. A Bengals win nets 0.14 point, but the chance of earning that point is so great and the chances of a crushing -1 point upset are so small that the Bengals pick is still a smart one, while picking the Browns is foolish despite the 14 point potential, akin to putting your money on a couple of roulette numbers (a more than 35 to 1 shot for each number) and hoping one happens to hit. (The Bengals did go on to win this early game 16-7)
It is with this methodology that I went to work on picking Friday's games... to be covered in Part 5.
Saturday, November 28, 2009
Ballhype, Golden Picks and EV, Part 3: The Sagarin Rating System and Finding a Better Use for It With EV
Your mileage may vary on the validity of the Sagarin ratings, but history shows a sustained accuracy in determining straight up winners across sports and levels. Even given the volatility of Sagarin's early season ratings, which carry over last year's performance until the current season adds enough data to stand on its own, not taking fully into account the current team's relative competitiveness... the ratings are to a great degree accurate, from 65-70%.
- Against the spread is another story, and to a system all systems seem to only have a consistent 47-55% accuracy against the spread, but that's another issue for down the road.
- While there are a variety of other predictive systems, I go with Sagarin given its longer history of accuracy (dating back to 1985), and because Sagarin covers all major sports compared to other systems focusing on certain sports. The methodology has a consistent accuracy across the board in all sports, college or pro.
As many others certainly do, I started out in the Ballhype contest using Sagarin's ratings as a guide. The only problem, of course, is that you typically end up picking the favorites, which comes with little reward since so many others are picking the favorites as well. You receive a small fraction of a point when you win, and lose the full one point when you lose. A single loss can undo several wins in an instant. However, when the underdog scores the upset, the Hensleys of the world pick up massive points and blow by everyone at once, even after missing on several other underdog picks where the favorite won.
Eventually, I started taking the Hensley route and picking all the underdogs in the pro games, as that's where a regular number of upsets occur. Even the worst pro teams often manage to win 30-40% of their games, and the best teams can lose 20-40% of theirs. Simple logic would indicate that scoring 5-10 points around 20-40% of the time and losing only one point 60-80% of the time will still lead to a big net gain.
At the same time, I noticed that many of the dozens of college games in football and basketball were such lopsided contests that picking the underdog still didn't make sense, such as the Florida football team against, say, Chattanooga. Even Hensley himself avoided picking an underdog in some contests. Many college games had 9-11 picks for the favorite and 0 for the underdog, and that favorite rolled to victory, a meager but assured 0.09 points for everyone.
Seeing that dual phenomenon, I felt there was a way to improve on Hensley's underdogs-only method, a middle ground where you could pick a favorite and have a good chance to win, while knowing when to pick an underdog. Every now and then Sagarin ratings would indicate an underdog was the most likely team to win but these instances weren't frequent.
However, some comparisons were closer than others. Some Sagarin comparisons showed lopsided differences between teams, while some leaned one way but were very close. Obviously, not all picks were equal, and I recalled my poker research and discussions of expected value. Knowing the relationship between probability and expected value, I realized that there had to be a direct correlation between the marginal difference in Sagarin ratings between two teams and the probability of each team winning. Putting that correlation and the idea of expected value together, I decided there had to be a way to devise a system that would maximize the return on each Ballhype Golden Picks selection.
"Why do this?", you ask. "Who cares? It's just a game." Yes it is. And so is, say, sportsbook wagering. The difference is that the latter nets you money when you win. Knowing that poker players utilize odds and expected value concepts to play poker profitably over the long run, I realize that EV concepts could cross apply to selecting teams provided systems of rating teams that showed a consistent correlation in picking winners. While point spreads provide an additional challenge over Ballhype in picking winners, I figured I could cross that bridge if/when I confirmed that such systems worked in the confines of the Ballhype contest, which operates on a similar scope with straight up picks.
The big obstacle was determining a consistent method for devising a team's probability to win. That was the next step in my research....
[Continued in Part 4]
- Against the spread is another story, and to a system all systems seem to only have a consistent 47-55% accuracy against the spread, but that's another issue for down the road.
- While there are a variety of other predictive systems, I go with Sagarin given its longer history of accuracy (dating back to 1985), and because Sagarin covers all major sports compared to other systems focusing on certain sports. The methodology has a consistent accuracy across the board in all sports, college or pro.
As many others certainly do, I started out in the Ballhype contest using Sagarin's ratings as a guide. The only problem, of course, is that you typically end up picking the favorites, which comes with little reward since so many others are picking the favorites as well. You receive a small fraction of a point when you win, and lose the full one point when you lose. A single loss can undo several wins in an instant. However, when the underdog scores the upset, the Hensleys of the world pick up massive points and blow by everyone at once, even after missing on several other underdog picks where the favorite won.
Eventually, I started taking the Hensley route and picking all the underdogs in the pro games, as that's where a regular number of upsets occur. Even the worst pro teams often manage to win 30-40% of their games, and the best teams can lose 20-40% of theirs. Simple logic would indicate that scoring 5-10 points around 20-40% of the time and losing only one point 60-80% of the time will still lead to a big net gain.
At the same time, I noticed that many of the dozens of college games in football and basketball were such lopsided contests that picking the underdog still didn't make sense, such as the Florida football team against, say, Chattanooga. Even Hensley himself avoided picking an underdog in some contests. Many college games had 9-11 picks for the favorite and 0 for the underdog, and that favorite rolled to victory, a meager but assured 0.09 points for everyone.
Seeing that dual phenomenon, I felt there was a way to improve on Hensley's underdogs-only method, a middle ground where you could pick a favorite and have a good chance to win, while knowing when to pick an underdog. Every now and then Sagarin ratings would indicate an underdog was the most likely team to win but these instances weren't frequent.
However, some comparisons were closer than others. Some Sagarin comparisons showed lopsided differences between teams, while some leaned one way but were very close. Obviously, not all picks were equal, and I recalled my poker research and discussions of expected value. Knowing the relationship between probability and expected value, I realized that there had to be a direct correlation between the marginal difference in Sagarin ratings between two teams and the probability of each team winning. Putting that correlation and the idea of expected value together, I decided there had to be a way to devise a system that would maximize the return on each Ballhype Golden Picks selection.
"Why do this?", you ask. "Who cares? It's just a game." Yes it is. And so is, say, sportsbook wagering. The difference is that the latter nets you money when you win. Knowing that poker players utilize odds and expected value concepts to play poker profitably over the long run, I realize that EV concepts could cross apply to selecting teams provided systems of rating teams that showed a consistent correlation in picking winners. While point spreads provide an additional challenge over Ballhype in picking winners, I figured I could cross that bridge if/when I confirmed that such systems worked in the confines of the Ballhype contest, which operates on a similar scope with straight up picks.
The big obstacle was determining a consistent method for devising a team's probability to win. That was the next step in my research....
[Continued in Part 4]
Part 1: Ballhype's Golden Picks Contest and Expected Value
For the last few weeks I've played Ballhype's Golden Picks Contest. You basically try to predict winners and you received a weighted score for correct picks depending on which team other players picked. You get -1 point for every pick you make that loses. How many points you get for winning picks depends on how many other players picked the team that won and the team that lost. The winning players split a pool that consists of one point plus one point for every player that picked the wrong team. This offers a small reward for picking a favorite, while winning underdogs net far more points.
For example, let's say Florida plays Troy, and 9 players pick Florida to win while 1 player picks Troy to score the upset. If Florida wins like they're supposed to, the nine winning players evenly split a pool of two points: One point for the moron that picked Troy to win (that moron loses a point for picking wrong), and one bonus point for picking a winner. Two points divided by nine equals 0.22 points per player, so by picking Florida you get 0.22 points.
But let's say half of Florida's team gets eaten by Tremors-like underground burrowing alligators that for some reason find the taste of Troy Footballers unappealing, the game continues on despite the howling protests of Florida fans who weren't eaten before SWAT soliders were able to execute the offending alligators, and Troy manages to score a huge upset.
The one dude who picked the upset gets 9 points for every poor schlub that picked Florida, plus one bonus point for making the right pick. For successfully predicting the upset (or guessing), the winning player gets a total of 10 points.
Now, an astute player named Rich Hensley has exposed the folly of such a system: By predicting upsets in most games, Hensley scores so many points every time an underdog wins that it more than offsets all the times he loses a point when the favorite wins. Each week he is usually the winning player.
I hang around near the top each week thanks to keeping abreast of the Sagarin ratings, along with having taken to frequently mimicing Hensley's tactic. At the same time I notice his sub-.500 record with his picks and have wondered... if there a more optimal method to making picks that can maximize my score. Because otherwise, the best I can do is to just pick underdogs and essentially tie with Hensley for the top rating, and what's the fun in that.
For example, let's say Florida plays Troy, and 9 players pick Florida to win while 1 player picks Troy to score the upset. If Florida wins like they're supposed to, the nine winning players evenly split a pool of two points: One point for the moron that picked Troy to win (that moron loses a point for picking wrong), and one bonus point for picking a winner. Two points divided by nine equals 0.22 points per player, so by picking Florida you get 0.22 points.
But let's say half of Florida's team gets eaten by Tremors-like underground burrowing alligators that for some reason find the taste of Troy Footballers unappealing, the game continues on despite the howling protests of Florida fans who weren't eaten before SWAT soliders were able to execute the offending alligators, and Troy manages to score a huge upset.
The one dude who picked the upset gets 9 points for every poor schlub that picked Florida, plus one bonus point for making the right pick. For successfully predicting the upset (or guessing), the winning player gets a total of 10 points.
Now, an astute player named Rich Hensley has exposed the folly of such a system: By predicting upsets in most games, Hensley scores so many points every time an underdog wins that it more than offsets all the times he loses a point when the favorite wins. Each week he is usually the winning player.
I hang around near the top each week thanks to keeping abreast of the Sagarin ratings, along with having taken to frequently mimicing Hensley's tactic. At the same time I notice his sub-.500 record with his picks and have wondered... if there a more optimal method to making picks that can maximize my score. Because otherwise, the best I can do is to just pick underdogs and essentially tie with Hensley for the top rating, and what's the fun in that.
Sunday, November 15, 2009
Handicapping and the Sagarin ratings
As a Vegas native, with access to teeming masses of sportsbook data (as well as parents who regularly brought home parlay and teaser cards), I dabbled in speculative handicapping while growing up, studying teams and trying to predict games, with understandably middling results. Obviously, as a minor, I didn't wager any actual money, and once of-age I maybe placed bets on games a handful of times.
Anyway, I'm conducting a sizable experiment on handicapping games using Sagarin ratings. I crunched predictions for every NFL, NHL, NBA and college basketball game today, and I'm going to note the results relative to the predictions. In other words, I expect the results to deviate from the predictions... the questions is how much and in what direction, if a correlation shows up.
I had been toying with the Sagarin numbers for a while, in using them to toy with Yahoo's league ranker polling system and in making predictions for Ballhype's Golden Picks contest. When I haven't deviated from Sagarin's ratings, I find the picks straight up are accurate roughly 55-65% of the time.
Ballhype's system rewards fractions of points for picking successful favorites and several points for picking successful underdogs, while docking you one point for every incorrect pick period. This system is allegedly gamed very easily by consistently making an astute series of underdog picks: a couple of players win regularly at the game this way, though the reward is nothing more than being a featured user on Ballhype's front page.
But of course, handicapped picks must be made against the spread. Since Sagarin uses a unique scoring system somewhat irrelevant to the scoring in each respective sport, there may not be a direct correlation between the scoring difference using Sagarin's White Owl Predictor and the actual score of the actual game in question. It can show the scope of difference in performance ability between teams, but does it consistently match the likely difference in score?
Google research has turned up little data: As with most subjects, research posted on the subject is typically shallow and poorly thought out at best. On paper, I will pick each individual game against the spread using the adjusted Predictor scores relative to the point spread to determine my initial picks. I'll note the results and look to note any sustained differences between the predicted margin of victory and the results. I expect plenty of white noise and variance in the short term: The key will be to find long run correlations.
Picks below the jump. Warning: Lots of raw data, listed in a clunky straightforward format. Have some painkillers ready if you're going to read them all. I'll try and streamline the data into a spreadsheet or chart format as I go along.
Anyway, I'm conducting a sizable experiment on handicapping games using Sagarin ratings. I crunched predictions for every NFL, NHL, NBA and college basketball game today, and I'm going to note the results relative to the predictions. In other words, I expect the results to deviate from the predictions... the questions is how much and in what direction, if a correlation shows up.
I had been toying with the Sagarin numbers for a while, in using them to toy with Yahoo's league ranker polling system and in making predictions for Ballhype's Golden Picks contest. When I haven't deviated from Sagarin's ratings, I find the picks straight up are accurate roughly 55-65% of the time.
Ballhype's system rewards fractions of points for picking successful favorites and several points for picking successful underdogs, while docking you one point for every incorrect pick period. This system is allegedly gamed very easily by consistently making an astute series of underdog picks: a couple of players win regularly at the game this way, though the reward is nothing more than being a featured user on Ballhype's front page.
But of course, handicapped picks must be made against the spread. Since Sagarin uses a unique scoring system somewhat irrelevant to the scoring in each respective sport, there may not be a direct correlation between the scoring difference using Sagarin's White Owl Predictor and the actual score of the actual game in question. It can show the scope of difference in performance ability between teams, but does it consistently match the likely difference in score?
Google research has turned up little data: As with most subjects, research posted on the subject is typically shallow and poorly thought out at best. On paper, I will pick each individual game against the spread using the adjusted Predictor scores relative to the point spread to determine my initial picks. I'll note the results and look to note any sustained differences between the predicted margin of victory and the results. I expect plenty of white noise and variance in the short term: The key will be to find long run correlations.
Picks below the jump. Warning: Lots of raw data, listed in a clunky straightforward format. Have some painkillers ready if you're going to read them all. I'll try and streamline the data into a spreadsheet or chart format as I go along.
Subscribe to:
Comments (Atom)